Backups através de redes degradadas (ex.: com perdas de pacotes) e Internet, na qual a conexão passa por diversos NATs, firewalls e roteadores, tendem a afetar bastante a performance e resiliência de conexões TCP. Erros como os que seguem podem acontecer no Bacula.
2023-04-20 21:03:38 ocspbacprdap02-sd JobId 11052: Fatal error: append.c:175 Error reading data header from FD. n=-2 msglen=20 ERR=I/O Error 2023-04-20 21:03:38 ocspbacprdap02-sd JobId 11052: Error: bsock.c:395 Wrote 23 bytes to client:10.16.152.200:9103, but only 0 accepted. #or 02-Aug 09:13 backupserver-dir JobId 110334: Fatal error: Network error with FD during Backup: ERR=Connection reset by peer
O uso do protocolo de congestão BBR nas máquinas do Director, Storage e File Daemons Linux do Bacula melhora significativa a resiliência para esses erros. o tempo de resposta e desempenho da rede também são aprimorados, na medida quer desconexões e perdas de pacote afetam muito menos as taxas de transferência.
O que é BBR?
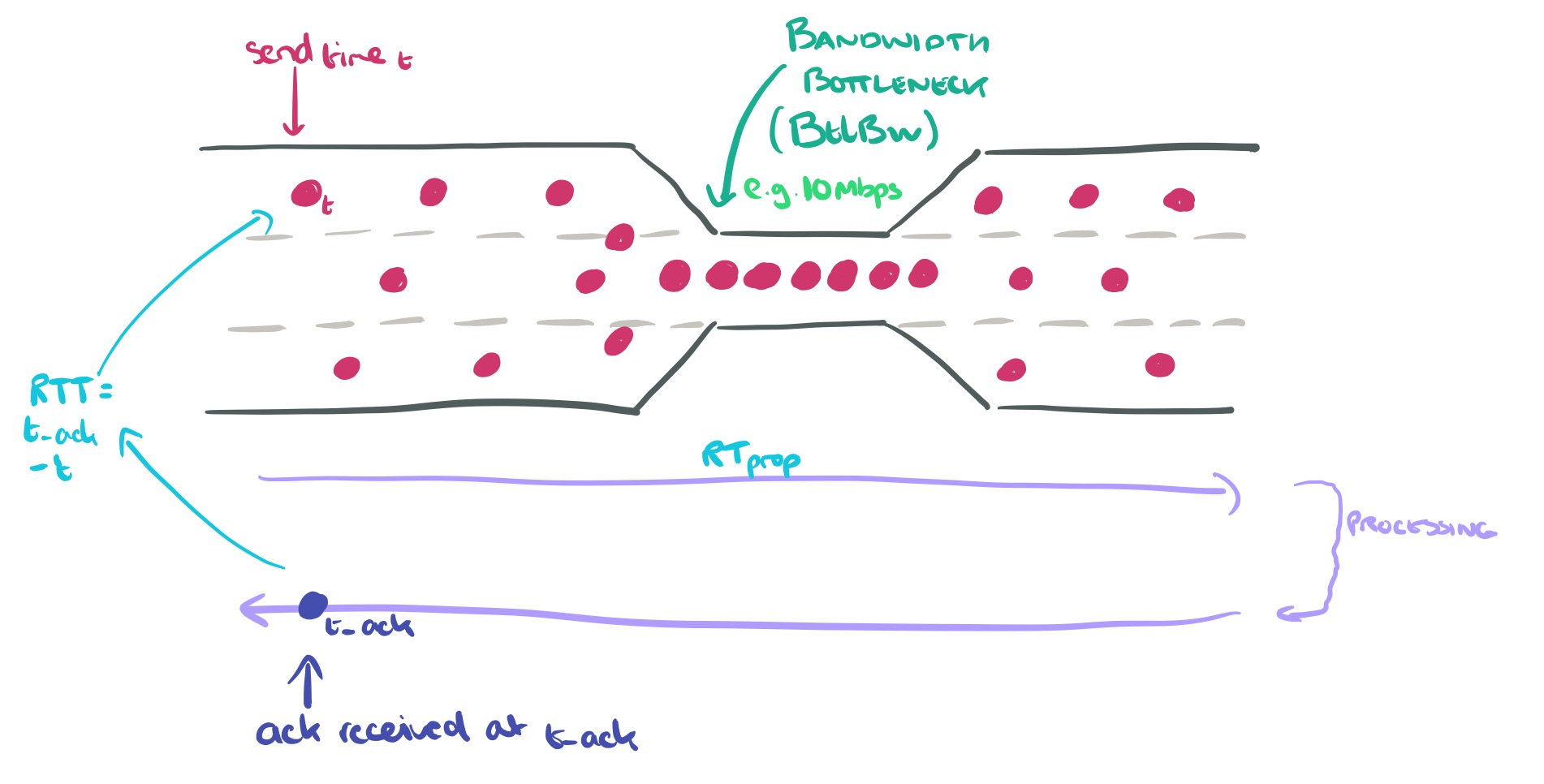
BBR é uma sigla para “Bottleneck Bandwidth and RTT” (Largura de Banda do Estrangulamento e Tempo de Resposta). O controle de congestão BBR calcula a taxa de envio com base na taxa de entrega (throughput) estimada a partir dos ACKs.
O BBR foi contribuído para o kernel Linux 4.9 em 2016 pelo Google.
O BBR aumentou significativamente o throughput e reduziu a latência para conexões nas redes internas da Google, bem como para os servidores da Web google.com e YouTube.
O BBR requer apenas alterações no lado do remetente, sem necessidade de mudanças na rede ou no lado do receptor. Portanto, ele pode ser implantado de forma incremental na Internet atual ou em data centers.
Como ativar o BBR
O script a seguir do Shell deve implementar o BBR.
modprobe tcp_bbr echo "tcp_bbr" > /etc/modules-load.d/bbr.conf echo "net.ipv4.tcp_congestion_control = bbr net.core.default_qdisc = fq" >> /etc/sysctl.conf sudo sysctl -p sysctl net.ipv4.tcp_congestion_control
Se o último comando deve exibir na tela o protocolo bbr, como a seguir.
root@hfaria-P65:~# sysctl net.ipv4.tcp_congestion_control net.ipv4.tcp_congestion_control = bbr
Caso outro protocolo seja exibido, reinicie o servidor.
Como testar o desempenho de rede?
iperf3 é uma utilidade para realizar testes de throughput de rede.
$ sudo apt-get install -y iperf3 Reading package lists... Done Building dependency tree Reading state information... Done The following additional packages will be installed: libiperf0 libsctp1 Suggested packages: lksctp-tools The following NEW packages will be installed: iperf3 libiperf0 libsctp1 ...
iperf3 pode usar a opção -C (ou –congestion) para escolher o algoritmo de controle de congestão. Em nossos testes, podemos especificar o BBR
-C, --congestion algo
Set the congestion control algorithm (Linux and FreeBSD only). An older --linux-congestion synonym
for this flag is accepted but is deprecated.
iperf -C bbr -c example.com # replace example.com with your test target
Nota:
O BBR TCP é apenas do lado do remetente, portanto, você não precisa se preocupar se o receptor suporta o BBR. Observe que o BBR é muito mais eficaz quando se utiliza o FQ (fair queuing) para ajustar o ritmo dos pacotes para, no máximo, 90% da taxa de linha.
Como posso monitorar as conexões TCP BBR no Linux?
Você pode usar o ss (outra utilidade para investigar sockets) para monitorar as variáveis de estado do BBR, incluindo a taxa de pacing, cwnd, estimativa de largura de banda, estimativa de min_rtt, etc.
Exemplo de saída do ss -tin:
$ ss -tin
State Recv-Q Send-Q Local Address:Port Peer Address:Port Process
ESTAB 0 36 10.0.0.55:22 123.23.12.98:61030
bbr wscale:6,7 rto:292 rtt:91.891/20.196 ato:40 mss:1448 pmtu:9000 rcvmss:1448 advmss:8948 cwnd:48 bytes_sent:95301
bytes_retrans:136 bytes_acked:95129 bytes_received:20641 segs_out:813 segs_in:1091 data_segs_out:792 data_segs_in:481
bbr:(bw:1911880bps,mrtt:73.825,pacing_gain:2.88672,cwnd_gain:2.88672) send 6050995bps lastsnd:4 lastrcv:8 lastack:8
pacing_rate 5463880bps delivery_rate 1911928bps delivered:791 app_limited busy:44124ms unacked:1 retrans:0/2
dsack_dups:1 rcv_space:56576 rcv_ssthresh:56576 minrtt:73.825
Abaixo, os campos a seguir podem aparecer:
ts show string "ts" if the timestamp option is set
sack show string "sack" if the sack option is set
ecn show string "ecn" if the explicit congestion notification option is set
ecnseen
show string "ecnseen" if the saw ecn flag is found in received packets
fastopen
show string "fastopen" if the fastopen option is set
cong_alg
the congestion algorithm name, the default congestion algorithm is "cubic"
wscale:<snd_wscale>:<rcv_wscale>
if window scale option is used, this field shows the send scale factor and receive scale factor
rto:<icsk_rto>
tcp re-transmission timeout value, the unit is millisecond
backoff:<icsk_backoff>
used for exponential backoff re-transmission, the actual re-transmission timeout value is
icsk_rto << icsk_backoff
rtt:<rtt>/<rttvar>
rtt is the average round trip time, rttvar is the mean deviation of rtt, their units are mil‐
lisecond
ato:<ato>
ack timeout, unit is millisecond, used for delay ack mode
mss:<mss>
max segment size
cwnd:<cwnd>
congestion window size
pmtu:<pmtu>
path MTU value
ssthresh:<ssthresh>
tcp congestion window slow start threshold
bytes_acked:<bytes_acked>
bytes acked
bytes_received:<bytes_received>
bytes received
segs_out:<segs_out>
segments sent out
segs_in:<segs_in>
segments received
send <send_bps>bps
egress bps
lastsnd:<lastsnd>
how long time since the last packet sent, the unit is millisecond
lastrcv:<lastrcv>
how long time since the last packet received, the unit is millisecond
lastack:<lastack>
how long time since the last ack received, the unit is millisecond
pacing_rate <pacing_rate>bps/<max_pacing_rate>bps
the pacing rate and max pacing rate
rcv_space:<rcv_space>
a helper variable for TCP internal auto tuning socket receive buffer
Exemplos de Melhoria de Throughput TCP
Do Google
A Pesquisa do Google e o YouTube implementaram o BBR e obtiveram melhorias no desempenho do TCP.
Aqui estão exemplos de resultados de desempenho para ilustrar a diferença entre o BBR e o CUBIC:
- Resiliência à perda aleatória (por exemplo, devido a buffers rasos):Considere um teste netperf TCP_STREAM com duração de 30 segundos em um caminho emulado com um gargalo de 10 Gbps, RTT de 100 ms e taxa de perda de pacotes de 1%. O CUBIC obtém 3,27 Mbps, enquanto o BBR alcança 9150 Mbps (2798 vezes mais alto).
- Baixa latência com os buffers inflados comuns nos links da última milha hoje em dia:Considere um teste netperf TCP_STREAM com duração de 120 segundos em um caminho emulado com um gargalo de 10 Mbps, RTT de 40 ms e buffer de gargalo de 1000 pacotes. Ambos utilizam totalmente a largura de banda do gargalo, mas o BBR consegue fazer isso com um RTT médio 25 vezes menor (43 ms em vez de 1,09 segund
Da AWS CloudFront
Durante março e abril de 2019, a AWS CloudFront implementou o BBR. De acordo com o blog da AWS: ‘Controle de Congestão TCP BBR com a Amazon CloudFront
O uso do BBR no CloudFront tem sido globalmente favorável, com ganhos de desempenho de até 22% de melhoria no throughput agregado em várias redes e regiões.
De Shadowsocks
Tenho um servidor Shadowsocks em execução em um Raspberry Pi. Sem o BBR, a velocidade de download do cliente é de cerca de 450 KB/s. Com o BBR, a velocidade de download do cliente melhora para 3,6 MB/s, o que é 8 vezes mais rápido do que o padrão.
BBR v2
Há um trabalho em andamento para o BBR v2, que ainda está na fase alfa.
Resolução de Problemas
sysctl: definindo a chave ‘net.core.default_qdisc’: Arquivo ou diretório não encontrado
sysctl: setting key "net.core.default_qdisc": No such file or directory
A razão é que o módulo do kernel tcp_bbr ainda não foi carregado. Para carregar o tcp_bbr, execute o seguinte comando
sudo modprobe tcp_bbr
Para verificar se o tcp_bbr está carregado, use o lsmod, por exemplo, no seguinte comando, você deverá ver a linha tcp_bbr:
$ lsmod | grep tcp_bbr tcp_bbr 20480 3
“Se o comando sudo modprobe tcp_bbr não funcionar, reinicie o sistema